1. Introduction
The purpose of this report is to indicate options available for the development of
a technical infrastructure to support research data management (RDM) at the
University of Sheffield. RDM, its situation within academic research and recent
drivers towards change are defined. The processes involved in RDM and the
elements of the supporting technical infrastructure are examined. The local
context, of RDM technical infrastructure at the University of Sheffield and
collaborating institutions, is explored.
The range of technical infrastructure components available and
evaluations of these components are reviewed. Instances of fully-functioning
RDM technical infrastructure and many of the recent research projects that
developed and piloted RDM technical infrastructure components are briefly
described. Finally, recommendations for suitable technical infrastructure
components are proposed.
1.1. Research
Data Management
The
research data collected to test a research assertion must be managed in an
appropriate manner to be considered good research practice. Good RDM practice
is now required of researchers by many research institutions and by most
research funders. Increasingly research funders are demanding long-term
curation of some of the data resulting from the research they fund, so that
they may be available for re-use. The value of those data and the impact of the
original research are increased by re-use. RDM may be considered to involve
three broad areas of activity:-
- Data
management planning, during the research proposal and grant application
stage.
- Looking
after ‘live’ or ‘active’ data as they are collected, processed, shared and
stored.
- Data Stewardship -
Long-term curation of research data and data publishing, making data
discoverable and reusable.
1.2. Research
data management drivers
JISC[i] have
supported the development of RDM practice over the last fourteen years by
funding projects involving HEIs through a number of programmes, in particular
the Managing Research Data Programmes 2009-11[ii] and 2011-13[iii]. The DCC[iv] was
established in 2004 with JISC funding, to support expertise and practice in
RDM. Since 2011 the DCC have offered tailored support in the development of
policy, services and infrastructure for Higher Education Institutions, and are
the foremost source for information and advice in the development of RDM
infrastructure (Jones et al. 2013). Infrastructure refers to the
hardware, software and human resources necessary to support the RDM services
and processes. This report focuses on the technical infrastructure, the
software and hardware components available.
The need
for good RDM practice is recognised by all stakeholders involved in the
research process. These include:
- Researchers,
who may be part of a research project team, which may include members of
many different institutions. Researchers need to secure their data against
loss or unauthorised access. Making data available to reuse allows
verification, promotes integrity and increases research impact.
- The
research institution (may be a HEI) or body employing
the researcher and providing the facilities. Research data may be
considered part of an institution’s special collections. Institutions
will also wish to minimise risk to the data and damage to their
reputation.
- The
research funder (usually a research council,
charity or a HEI) who may mandate RDM procedures such as the creation of a
Data Management Plan (DMP) and the deposit of data to repositories.
Research Funders may support facilities for data curation such as data
centres. Funders wish to increase
the return on their funding, through the reuse of data.
- Governments, who fund research councils and other funding bodies, are concerned to derive as much value as possible from publicly funded research.
- Publishers of research papers, who may publish the underlying data, seeking to add value to the publication process.
The
EPSRC policy framework on research data[v],
published in May 2011, puts forward the EPSRC expectations[vi] of
organisations receiving EPSRC funding, concerning the management and provision
of access to EPSRC funded research data. These nine expectations were developed
from seven guiding principles[vii]
which are aligned with the RCUK common principles on data policy[viii].
Institutitions in receipt of EPSRC funding are expected to be fully compliant
with these expectations by 1st May 2015. In terms of RDM
Infrastructure, the pertinent expectations (EPSRC, 2013) are:
“Research
organisations will ensure that appropriately structured metadata describing the
research data they hold is published (normally within 12 months of the data
being generated) and made freely accessible on the internet; in each case the
metadata must be sufficient to allow others to understand what research data
exists, why, when and how it was generated, and how to access it”
“Research
organisations will ensure that EPSRC-funded research data is securely preserved
for a minimum of 10-years from the date that any researcher ‘privileged access’
period expires or, if others have accessed the data, from last date on which
access to the data was requested by a third party;”
“Research
organisations will ensure that effective data curation is provided throughout
the full data lifecycle... The full range of responsibilities associated with
data curation over the data lifecycle will be clearly allocated within the
research organisation, and where research data is subject to restricted access
the research organisation will implement and manage appropriate security
controls;”
The
University of Sheffield Research Data Management Policy[ix] was
developed in response to the RCUK principles and EPSRC expectations. Of the
eight points of policy, the following (The University of Sheffield, Research
and Innovation Services, 2014) are particularly relevant for RDM
Infrastructure:
“The primary responsibility
for effective research data management during the course of research projects
lies with lead researchers. However, all researchers, including postgraduate
and undergraduate students undertaking research, have a personal responsibility
to manage effectively the data they create.”
“Unless
the terms of research grants or contracts provide otherwise, data generated by
research projects are the property of the University of Sheffield. Researchers
should exercise care in assigning rights in data to publishers or other
external agencies.”
“The University
will provide support for research data management, including… ...Additional
infrastructure and services for research data management, to be developed in
consultation with researchers.”
The
research institution is the body responsible for providing the researcher with
facilities for research and is therefore responsible for providing the
researcher with the necessary infrastructure and services to support RDM.
Design of this infrastructure must be based upon the researcher workflow, so as
not to burden the researcher with additional work or by changing their
practices, and where possible, making RDM processes virtually automatic and
invisible to the researcher.
1.3. Research
data lifecycle
Data
collected during a research project will include the research data themselves;
experimental, observational, modelled data etc. together with the metadata that
describes these data in detail and documentation describing the context of the
research, details of the research project and the processes involved. Data here
will be defined as the numerical and textual information collected by analysis
or measurement from the research samples or objects – but not the samples or
objects themselves. For example, a collection of images or of tissue samples
will not be considered data until there is textual or numerical information,
such as identifiers (names or ID numbers), descriptions and relationships,
associated with them. In this document, data refers to digital data, although
the same management principles apply to analogue data formats. However, it is
best practice to digitise research data, making its discovery and reuse easier.
From
the initial drawing-up of a research proposal and grant application, data will
be collected and managed. This includes documentation about the project, people
and bodies involved, grant application, data management plans, experimental
protocols, possibly test data or data collected from previous projects for
re-use and a literature review or bibliography.
Once
underway, a research project will collect or create raw data, which, during the
project, will usually be processed to create derived or processed data. There
may be many different iterations of processing, resulting in many sets of
derived data. Eventually a set of ‘results’ data will be selected as the basis
of the research publication(s) output by the project. All these sets of data
can be considered active data, which will need to be quickly
accessible and easily shared between collaborators. All these sets of active
data will need appropriate documentation to describe the processes involved in
their creation and modification.
After the
project has finished, researchers will need to select data for curation on a
long-term basis. This
may have been decided in agreement with the research funder during the initial
planning stage of the project. Curation in the context of RDM, refers to
archiving, preservation and adding value through transformation and reuse.
These archive data selected for curation, may need further processing
(validation, cleaning, anonymisation or redaction) before submitting to an
appropriate repository. The associated metadata will be needed to provide the
necessary information for citation and re-use. There may be the facility to add
new metadata or documentation, generated by data reuse, to the curated dataset.
Data not required for curation needs to be disposed of in an appropriate
manner.
1.4. Data
documentation, metadata and data collections
Data need
to be documented to be understood and managed. Data documentation indicates the conditions and processes involved
in the creation or collection of the data, the processing of the data and the
context of the research. Detailed documentation is essential for verification
and reuse. Adequate data documentation is necessary to determine provenance,
licensing and access arrangements and preservation requirements. Research data
need to be documented at three levels:
- Project
level – providing an overview of the research context and design.
- File level – describe the relationships between files or database tables.
- Item level – describing, for example, the meaning of a variable in a table. (Research Data Mantra, 2014, UKDA, 2014)
Metadata are a
highly structured subset of core data documentation. Metadata are structured so
that they may be indexed and stored within a database, thereby facilitating
data organisation and discovery, and machine to machine interoperability. By
considering its function, metadata may be divided into three layers:
- Core
metadata (Datacite, 2011, p. 8) or Catalogue
metadata - creator name, publisher, title and an identifier are required
for discovery and correct citation of the data. This could possibly
include some subject description or classification details.
- Detail metadata or
Administrative metadata – provides generic dataset description. This
includes access, preservation and technical metadata, and is required for
the long-term curation of the data. This will include more detailed
classification / subject description.
- Discipline
specific metadata (also known as Reuse metadata) – This documents aspects
of the dataset that will be of interest to researchers wishing to validate
the research process or re-use the data. This will consist of experimental
protocols, instrument settings, and relationships with other elements of
the dataset, other files within a data collection or other data
collections. This will provide very detailed classification / subject
description, providing the fine-grained attributes of data necessary for
accurate discovery and location of elements within a dataset. Discipline
specific information is frequently held in unstructured formats, so could
be considered data documentation rather than metadata. (Ensom, 2013 and IDMB, 2011)
Data
collections
are typically organised by reference to a particular survey or research topic
and may cover a specific geographic area and time period. The UKDA defines a
data collection as typically comprised of three components: data, documentation
and metadata. Code is occasionally considered a fourth component (Ensom and Corti, 2012, p. 3).
1.5. Data
repository or Data registry?
A
repository is a content management system which may be considered to consist of
three elements – a user interface front-end, and a database layer and storage
layer back-end.
The database holds records of entities, consisting of metadata elements as a
series of fields. The storage layer, containing the actual data bitstreams, may
be a file system on the repository server, or a file system on a local server
or a remote server that is independent of the repository system. This may
include cloud storage or a hybrid storage system. Usually in a repository
system, only metadata records are held within the database, not the data
objects themselves. This is due to the larger size of data objects which results
in slower indexing / access speeds. Storage designation is handled by a storage
controller or storage resource broker.
Different
repository systems may be configured for different organisational structures.
Repositories may range in the granularity of data described: The entity
described by a repository record, the data object, may be a single row within a
database or spreadsheet, a single file, or a collection of interrelated files
constituting a dataset. In the Essex ePrints [6.1.4][x]
context, the ‘eprint’, the key entity, is the ‘data collection’
which consists of a set of metadata and files (Ensom and Wolton, 2012). Datasets may be grouped as
collections or groups, the ‘User’ entities may be grouped as a ‘Community’.
A
‘Data registry’, or ‘Data catalogue’ or ‘Metadata store’, is a repository
system that holds only metadata records. The data themselves are held on a
local or remote file storage system, so the metadata record points to the data
store filepath or URL. By using the appropriate metadata standards, metadata
records may be exchanged between registries, giving rise to the possibility of
national and international registries. Repository systems were originally
designed to curate textual digital objects, but are now being modified to
curate digital objects of all formats and sizes, with the view of extending
their purpose to curate research data (Gutteridge, 2010). As
they have been designed to manage, curate and publish research outputs, they
may perhaps provide the ideal platform for a catalogue for the data underlying
the research outputs.
The ANDS[xi]
strategy has been to separate the data storage function from the cataloguing
function, the dissemination function and access control are provided by the
metadata store (ANDS, 2011b).
1.6. Research
data ecology
In
considering the implementation of an Institutional RDM technical
infrastructure, it can be useful to consider the ecological approach (Robertson et al. 2008), to gain a better understanding of the
interactions between repositories and services. The local infrastructure does
not exist in a vacuum and must interact with, and is dependent on, a diverse
range of entities and processes in the information ecosystem.
In
determining the place of a repository, registry or other infrastructure
component in the overall information ecosystem, it may be helpful to identify a
range of components by considering their data storage coverage and
specialisation (ANDS, 2011a), which may be:
·
Local – personal, project or
departmental server for active data storage.
·
Storage associated with an instrument
or facility.
·
Institutional storage for active data –
networked filestores.
·
Institutional repository for archive data.
·
Multi-institutional project data
storage (CARMEN [6.2.5] for example).
·
Research council data centre – for
archive data including longitudinal data.
·
Discipline based repository – for
active and archive data. National or International coverage.
Metadata
storage will have a similar range (ANDS, 2011b), which may be:
- Local, project and
instrument based metadata store – spreadsheets or databases associated
with the data.
- Institutional
data registry or repository.
- National
data registry (ANDS).
- Discipline
based metadata store – may be international, national or multi-institution
based.
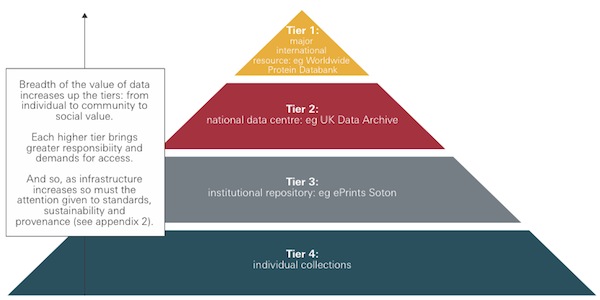
A number
of practitioners have suggested that, regarding research data curation, “the
Institutional repository is the repository of last resort” (Haywood, 2013), since discipline based repositories are
better configured for the types of data and specialised metadata formats
associated with the research community they serve. However the importance of
the institutional research data services (tier 3) in the hierarchy of rising
value and permanence (Figure 1. below) is emphasised in the Royal Society report ‘Science as an open enterprise’ (2012).

Figure 1. The data pyramid - a hierarchy of rising
value and permanence (Royal Society, 2012)
{kind=link}
This is reiterated
by Simon Hodson (2012),
who maintains that Institutional research data services are essential because:
- The institution is where
the data are created and can be captured. Institutions implementing RDM
infrastructure will make data discovery and curation possible.
- Joining
the gulf between curated data in national / international data services
and uncurated and inaccessible data in individual or project collections.
- Elevating data to national
/ international data services from temporary and inaccessible individual
collections. Important data collections may emerge as they become
discoverable.
The data
catalogue component of an institutional infrastructure would ideally adhere to
the formats and schemas used by a national data registry under development. The
existence of tools for interoperability and for deposit to the major data
centres should also be a consideration in the selection of a repository system.
1.7. Development
of RDM services
The
DCC have created a guide to developing RDM services at HEIs (Jones et al. 2013), which breaks down the development,
process into a number of components, as visualised in Figure 2.

Figure 2. The components of an RDM
service as envisaged by the DCC (Jones et al. 2013, p. 5)
The
approach to the development of RDM Services for HEIs, recommended by the DCC
involves:
- Assembling a steering
group composed of senior representatives of stakeholder group – senior
researchers and institutional support service managers.
- Appointing
an RDM service development group to undertake the work.
- Carrying
out a gap analysis, to determine gaps between current position and the
aimed-at future position, and requirements gathering surveys to determine
stakeholders needs.
- Development
of RDM policy and strategy. Developing a policy first may be useful as a
motivating factor, but may lead to problems if the proposed infrastructure
and services cannot be realised. Alternatively, the development of policy
may be subsequent to the defining of strategy.
- Designing services to meet local and external needs – putting in place the infrastructure required to support these services.
- Piloting these services to test that they are fit for purpose.
The
DCC have published a case study detailing the development and implementation of
an RDM strategy (Rans & Jones, 2013). Design of the technical
infrastructure required to support the RDM Service is considered below.
[v]
Engineering and Physical Sciences Research Council (EPSRC) policy framework on
research data http://www.epsrc.ac.uk/about/standards/researchdata/Pages/policyframework.aspx
[viii]
Research Councils UK (RCUK) common principles on data policy http://www.rcuk.ac.uk/research/datapolicy/
[ix]The
University of Sheffield Research Data Management Policy http://www.shef.ac.uk/ris/other/gov-ethics/grippolicy/practices/all/rdmpolicy
No comments:
Post a Comment